L0: 端到端RLVR 训练流水线与 Notebook Agent 框架

端到端 RLVR 训练探索
- 代码即动作, 在思维链中引入编程语言, 使Agent通过代码来思考
- 动态上下文管理, 智能体可以截断早期的动作和输出, 并把变量状态存储在Notepad中, 以便后续调用
- 在Github上获得了350+ stars, 技术文章被多家媒体转载
Limitation
- 模型参数限制了智能体的上限
- 基于Verl开发, 无法处理复杂的数据流
- 调研场景更依赖搜索引擎, 执行代码价值有限
自研万亿级模型分布式训练基础设施
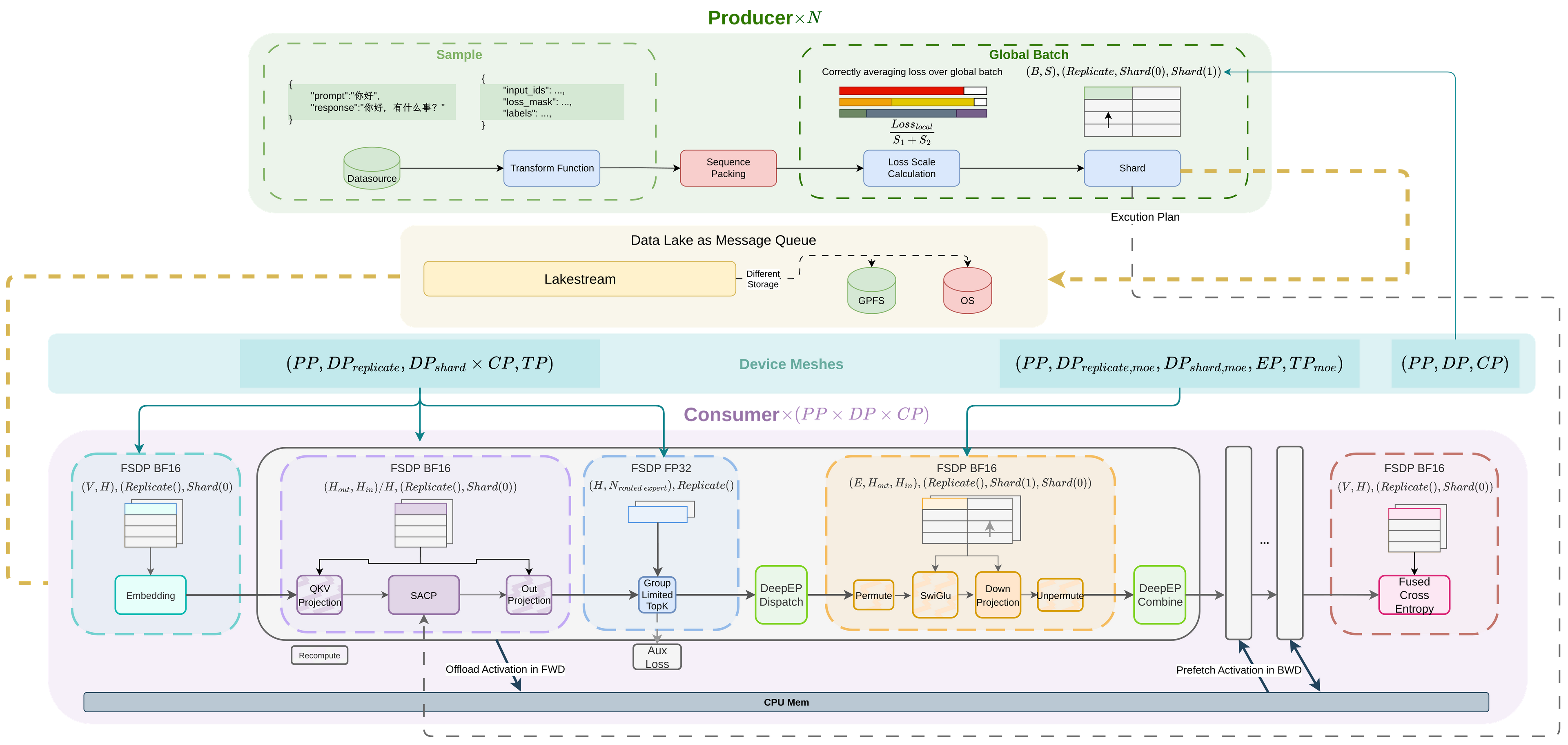
自研万亿级模型分布式训练基础设施
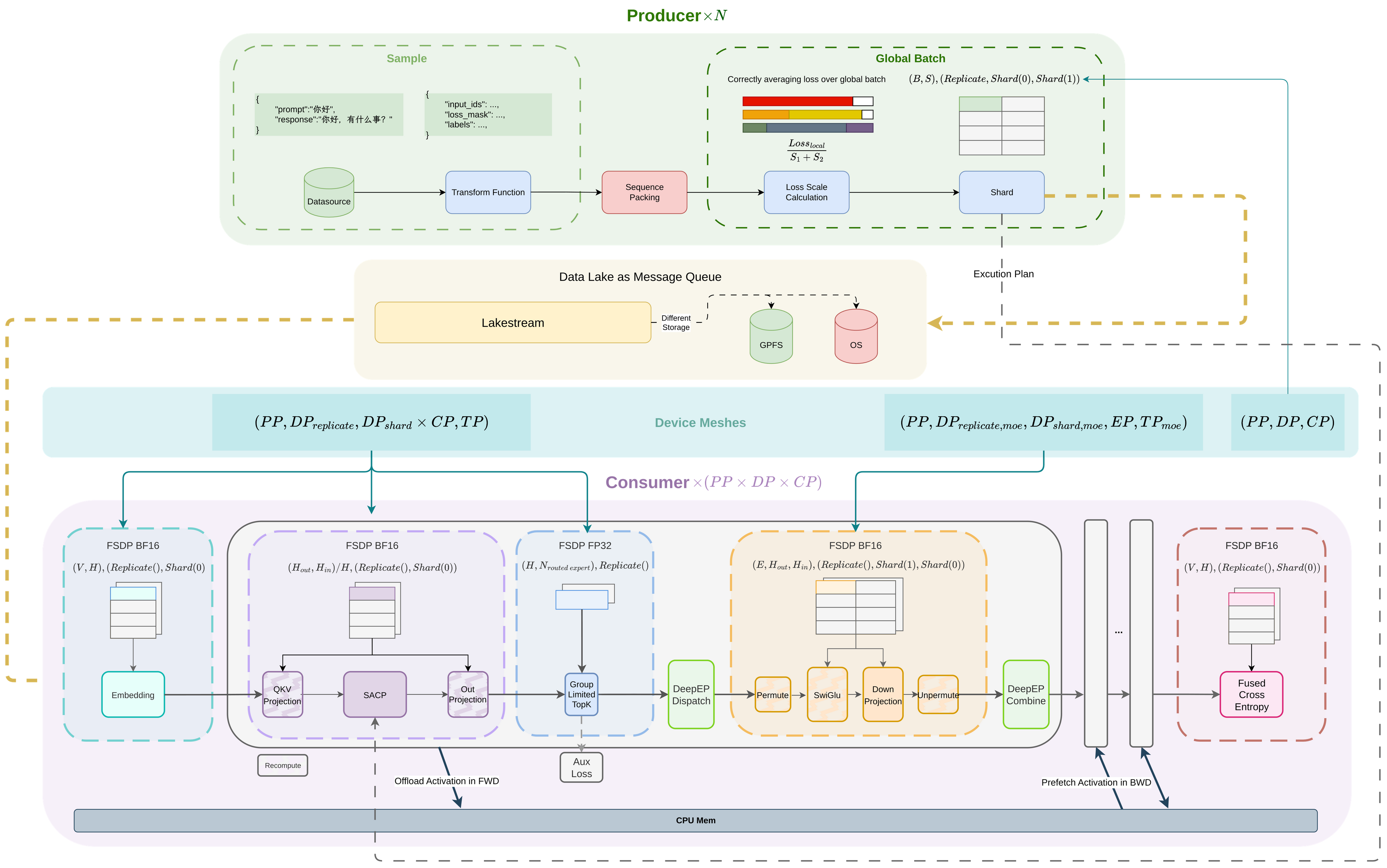
数据准备
- 序列感知的sequence packing策略, 支持全局的负载均衡优化及正确的全局loss scale计算,保证了分布式训练的数学等价性
数据传输优化
- 为大规模训练的高吞吐, 延迟不敏感的场景, 设计数据湖即是消息队列处理架构,
模型并行
- 以FSDP+CP为核心, 使用
DTensor+torch.compile实现了优雅高效的大规模模型并行训练 - MFU达到30%以上
建设大规模后训练数据流框架
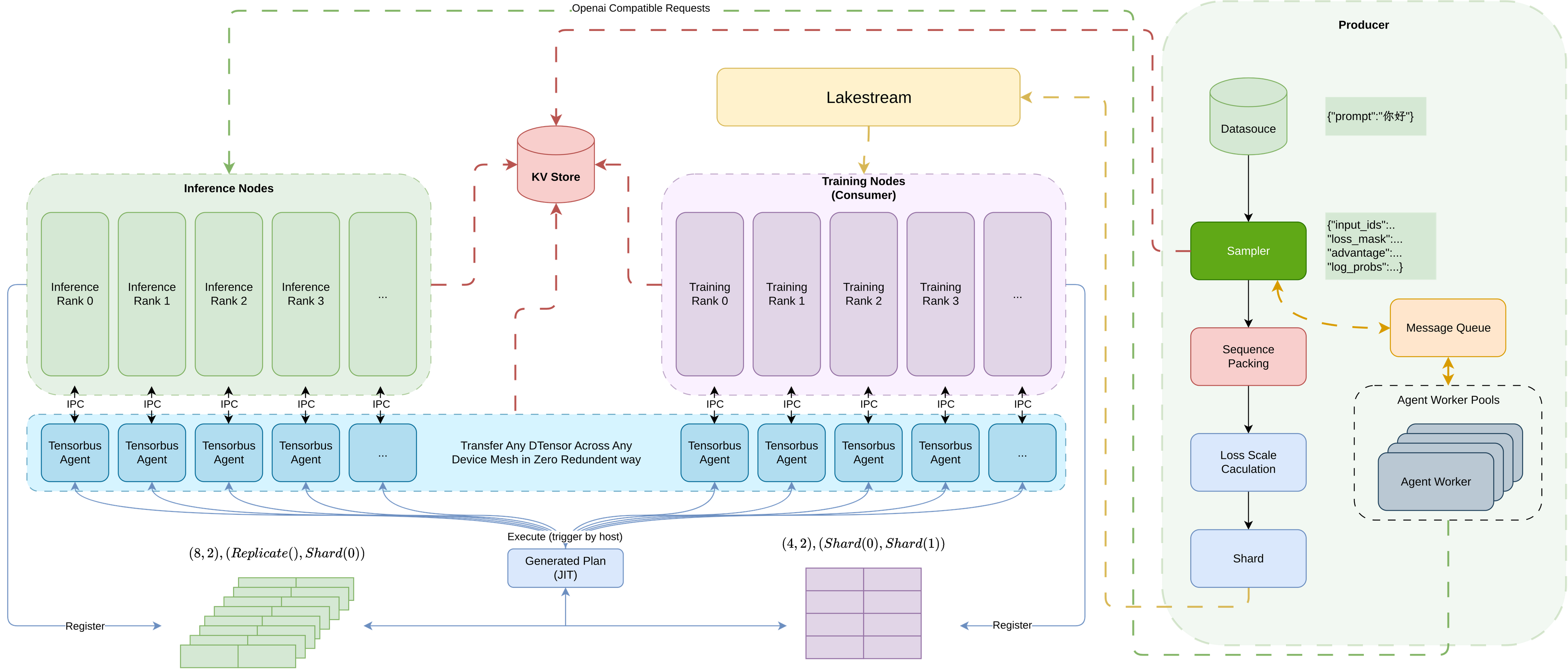
构建智能体数据合成与训练评测闭环体系
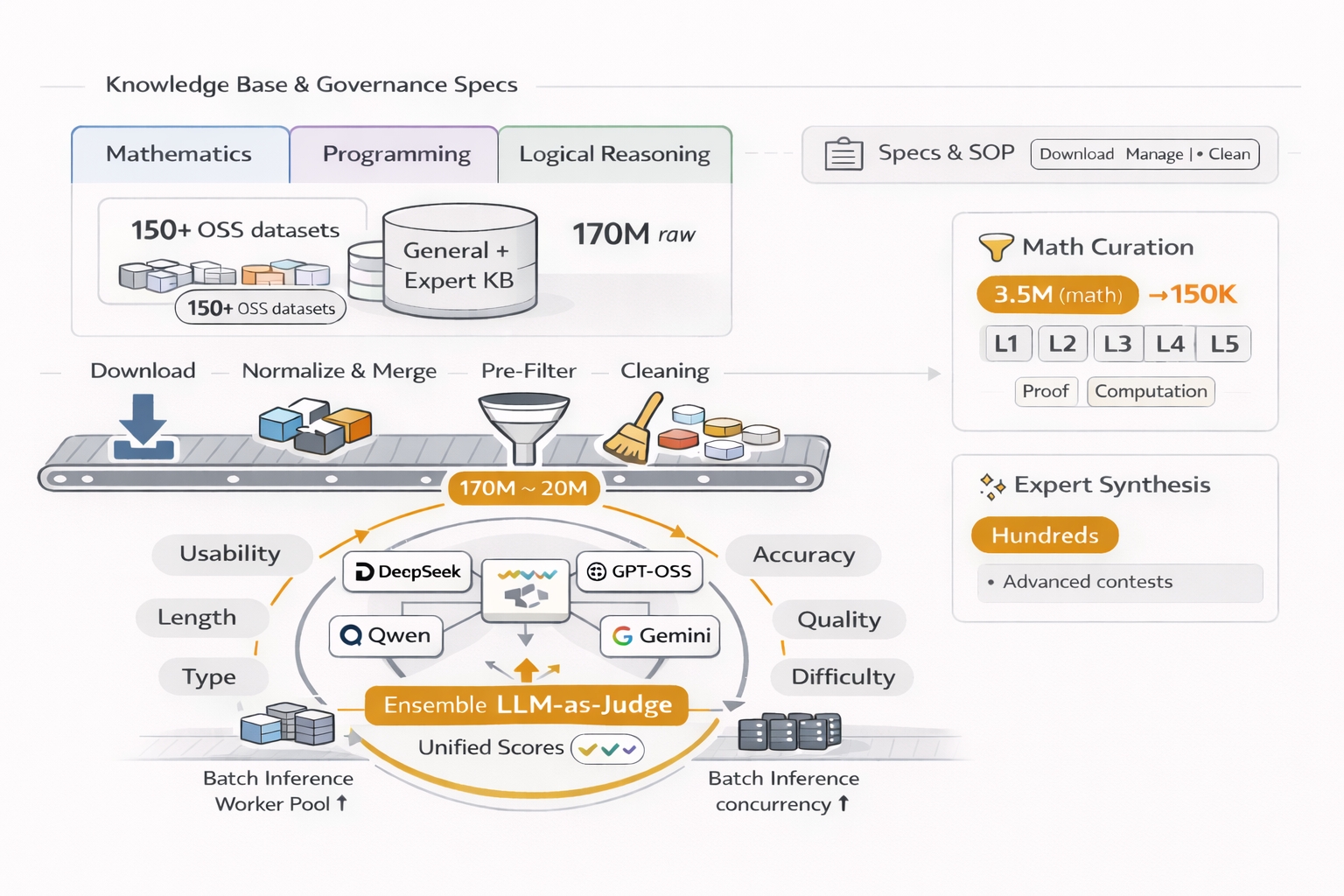
- 后训练知识库与数据治理规范: 建立覆盖数学、编程与通用逻辑推理的标准化体系,整合 150+ 开源数据集,完成从 1.7亿 原始数据到 2000万 高价值数据的清洗与预筛选。
- LLM-as-Judge 高质量合成流水线: 构建多维标注与分级合成体系,实现从 350万 到 15万 的精筛,沉淀分级题库及数百条专家级合成数据。
- 数据范式验证 围绕 Qwen3 Base/Thinking 开展数据驱动的闭环迭代,在 AIME(2.92)/HMMT(7.35)/GPQA(2.67) 等评测上全面实现 3% 左右的性能提升。
Agentic Grep: 通往智能上下文召回
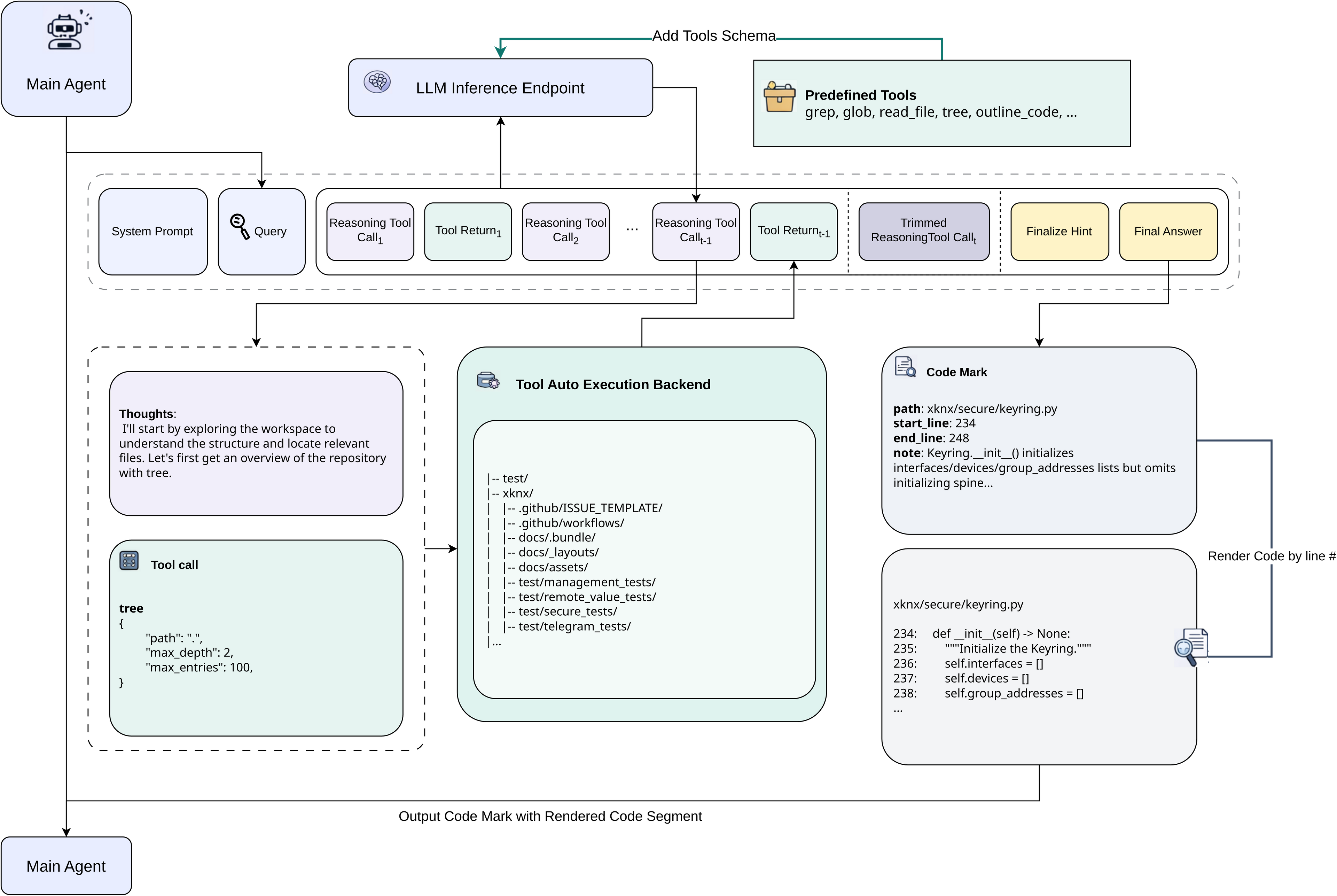
把上下文检索和代码定位作为一个智能体任务来处理,而不是传统的检索任务。
通过智能体的多轮交互,逐步缩小检索范围,最终定位到最相关的代码片段。
在该任务上, 目前的主流agent模型(KIIM-K2,MiniMax-2.1, CodeX, Deepseek V3.2等均在60%左右)
基于Deepseek-V3.2的3000条轨迹数据进行蒸馏, 将
Qwen3-30B的文件召回率从接近基线(带有关键词的BM25, 召回率24.74\%)提升近100%(24.11 \% \to 45.6\%), 超过了GPT-5.1(30.65\%)的表现。